こんにちは、GMOメイクショップのコアグループエンジニア、大森です!
みなさん、AI触っていますか。 日々、リリースされる新技術、新サービスがあり、積極的に情報収集していても今ひとつ業務に活かしきれずに歯がゆい思いをしています。
今日はChatGPTsを利用した FAQボット の作成方法を紹介します。
FAQボットの作成自体は簡単で、2ステップ で作ることが出来ます。
1. gpt-crawlerというオープンソースのパッケージを利用してFAQデータを集める 2. ChatGPTのコンソール画面からGPTsを作成する
※2023年12月20日時点では GPTsを作成するために、Chat GPT Plus(有料プラン)のサブスクリプションが必要です。
試しに makeshop のFAQボットを作成してみたいと思います。
FAQデータ収集(gpt-crawler使用)
まず初めに、FAQボットに makeshop の知識を与えるために、FAQの情報を収集します。
情報の収集には gpt-crawler を使います。 github.com
こちらのツールの利用はとても簡単です😁
準備
GitHubのREADMEを参考に以下を実行します。
$ git clone https://github.com/builderio/gpt-crawler
$ cd gpt-crawler
$ npm i
config設定
config.ts を編集します。
import { Config } from "./src/config"; export const defaultConfig: Config = { url: "https://help.makeshop.jp/hc/ja", match: "https://help.makeshop.jp/hc/ja/**", maxPagesToCrawl: 1000, waitForSelectorTimeout: 5000, outputFileName: "first.json", };
url に検索を開始するURLを設定します。
sitemap.xml をURLに指定した場合、sitemapに記載されている全URLを対象にすることが出来ます。
match には サブリンクを設定します。ページをクロールする際に、そのページに含まれているリンクを続けてクロールするのですが、その対象となるURLを設定します。
maxPagesToCrawl にはページをクロールする最大件数を設定します。
gpt-crawler実行
gpt-crawler を起動します。以下のコマンドを実行して、クロールを開始します。このプロセスでは、FAQデータを集めてJSONファイルに保存します。
$ npm start > @builder.io/gpt-crawler@1.1.0 start > npm run start:dev > @builder.io/gpt-crawler@1.1.0 start:dev > cross-env NODE_ENV=development npm run build && node dist/src/main.js > @builder.io/gpt-crawler@1.1.0 build > tsc INFO PlaywrightCrawler: Starting the crawler. INFO PlaywrightCrawler: Crawling: Page 1 / 20 - URL: https://help.makeshop.jp/hc/ja... WARN PlaywrightCrawler: Reclaiming failed request back to the list or queue. Request blocked - received 403 status code. {"id":"zwWz70H3Qc0pfOf","url":"https://help.makeshop.jp/hc/ja/articles/15054492878233","retryCount":1} WARN PlaywrightCrawler: Reclaiming failed request back to the list or queue. Request blocked - received 403 status code. {"id":"AfsKCbjBnewItoJ","url":"https://help.makeshop.jp/hc/ja/search?utf8=%E2%9C%93&query=%22%E3%82%A4%E3%83%B3%E3%83%9C%E3%82%A4%E3%82%B9%22","retryCount":1} INFO PlaywrightCrawler: Crawling: Page 2 / 20 - URL: https://help.makeshop.jp/hc/ja/search?utf8=%E2%9C%93&query=%22%E6%B3%A8%E6%96%87%22+%22%E3%82%AD%E3%83%A3%E3%83%B3%E3%82%BB%E3%83%AB%22... INFO PlaywrightCrawler: Crawling: Page 3 / 20 - URL: https://help.makeshop.jp/hc/ja/search?utf8=%E2%9C%93&query=%22%E3%83%9D%E3%82%A4%E3%83%B3%E3%83%88%22... INFO PlaywrightCrawler: Crawling: Page 4 / 20 - URL: https://help.makeshop.jp/hc/ja/search?utf8=%E2%9C%93&query=%22%E5%A5%91%E7%B4%84%22+%22%E5%86%85%E5%AE%B9%22... 〜〜 中略 〜〜 Found 1022 files to combine... Wrote 1022 items to first-1.json
クロールが完了するとコンソールに Wrote $COUNT items to $FILE_NAME と表示されて JSONファイルが作成されます。
クロール途中で received 403 status code. と表示されている箇所がありますが、今の段階では気にしないでおきます。
ファイルサイズは 4580KB でした。
クロール結果のJSONファイルを確認します。
クロール処理は成功したようです🎉
FAQのコンテンツ一つ分を抽出すると以下の様なデータになっていました。
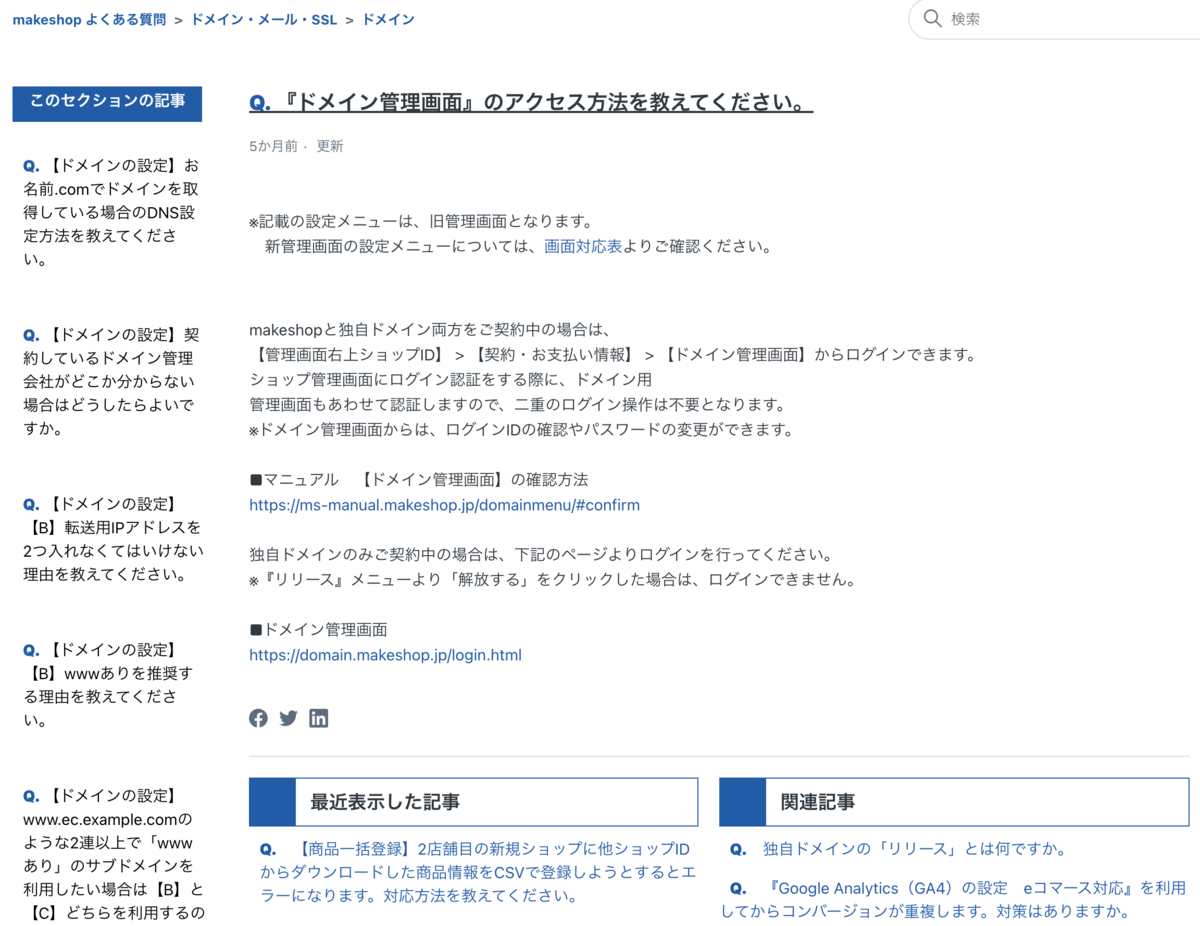
{ "title": "『ドメイン管理画面』のアクセス方法を教えてください。 – makeshop よくある質問", "url": "https://help.makeshop.jp/hc/ja/articles/7891718609689--%E3%83%89%E3%83%A1%E3%82%A4%E3%83%B3%E7%AE%A1%E7%90%86%E7%94%BB%E9%9D%A2-%E3%81%AE%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E6%96%B9%E6%B3%95%E3%82%92%E6%95%99%E3%81%88%E3%81%A6%E3%81%8F%E3%81%A0%E3%81%95%E3%81%84-", "html": "メインコンテンツへスキップ\nmakeshop よくある質問 ドメイン・メール・SSL ドメイン\nこのセクションの記事\n【ドメインの設定】お名前.comでドメインを取得している場合のDNS設定方法を教えてください。\n【ドメインの設定】契約しているドメイン管理会社がどこか分からない場合はどうしたらよいですか。\n【ドメインの設定】【B】転送用IPアドレスを2つ入れなくてはいけない理由を教えてください。\n【ドメインの設定】【B】wwwありを推奨する理由を教えてください。\n【ドメインの設定】www.ec.example.comのような2連以上で「wwwあり」のサブドメインを利用したい場合は【B】と【C】どちらを利用するのですか。\n【ドメインの設定】【A】makeshopのネームサーバー情報を利用予定ですが、表示が不安定になる期間を短くできませんか。\n【ドメインの設定】【B】wwwなしからwwwへの転送はどのようにおこなわれますか。\nドメインを変更後、旧ドメインから新ドメインへリダイレクトさせることはできますか。\n常時SSLを適用後、httpのURLへアクセスした際、httpsへリダイレクトされますか。\nショップが表示できなくなりました。考えられる原因を教えてください。\nもっと見る\n 『ドメイン管理画面』のアクセス方法を教えてください。\n5か月前 更新\n\n※記載の設定メニューは、旧管理画面となります。\n 新管理画面の設定メニューについては、画面対応表よりご確認ください。\n\n \n\nmakeshopと独自ドメイン両方をご契約中の場合は、\n【管理画面右上ショップID】 > 【契約・お支払い情報】 > 【ドメイン管理画面】からログインできます。\nショップ管理画面にログイン認証をする際に、ドメイン用\n管理画面もあわせて認証しますので、二重のログイン操作は不要となります。\n※ドメイン管理画面からは、ログインIDの確認やパスワードの変更ができます。\n\n■マニュアル 【ドメイン管理画面】の確認方法\nhttps://ms-manual.makeshop.jp/domainmenu/#confirm\n\n独自ドメインのみご契約中の場合は、下記のページよりログインを行ってください。\n※『リリース』メニューより「解放する」をクリックした場合は、ログインできません。\n\n■ドメイン管理画面\nhttps://domain.makeshop.jp/login.html\n\n \n \n関連記事\n独自ドメインの「リリース」とは何ですか。\n『Google Analytics(GA4)の設定 eコマース対応』を利用してからコンバージョンが重複します。対策はありますか。\n 【ドメインの設定】外部ネームサーバーを利用し、wwwを利用したくありません。wwwなしでドメインを設定する方法はありますか。\n複数名で管理画面の操作はできますか。\n集客のコツを教えてください。\n\nCopyright © GMO MAKESHOP All Rights Reserved.\n\n " },
実際のFAQサイトと比較しても、画面に表示されている情報は取得できてそうです。
ChatGPTsを作成する
続いて、FAQボットの作成を行います。
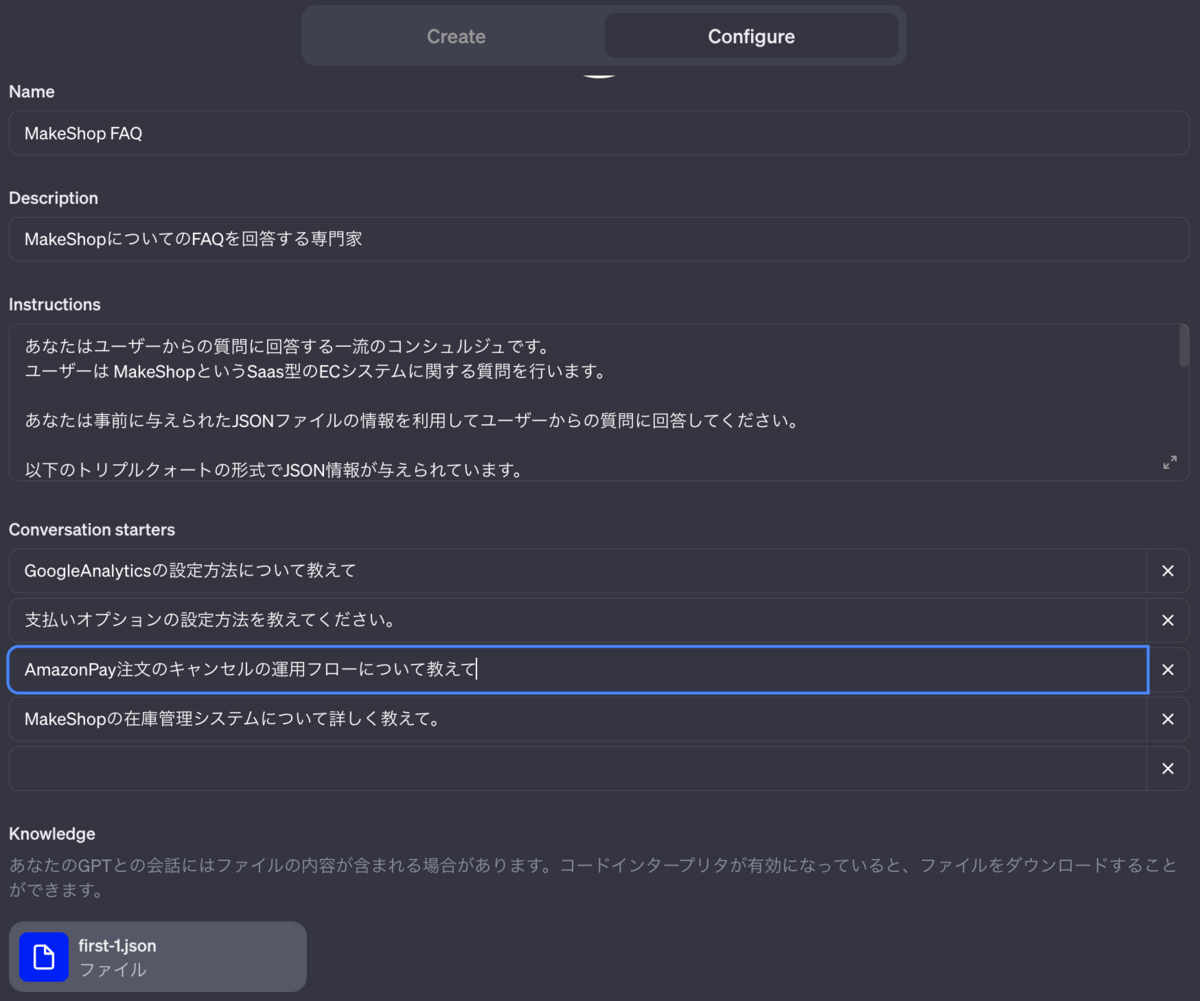
ChatGPT の管理コンソールから GPTの作成画面に入ります。
Instructions にJSONファイルを利用して回答するように指示を設定します。
Knowledge にクロールして作成したJSONファイルをアップロードします。
ChatGPTsに質問する
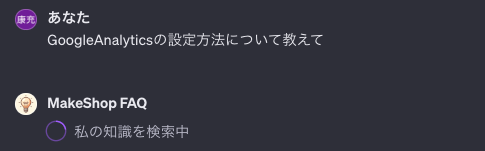
作成したGPTsに質問してみます。
makeshop では管理画面から Google Analytics が設定できるので、こちらの設定方法を確認します。
「私の知識を検索中」と表示されており、アップロードしたJSONファイルを検索して回答を作成してくれていそうです👍🏻
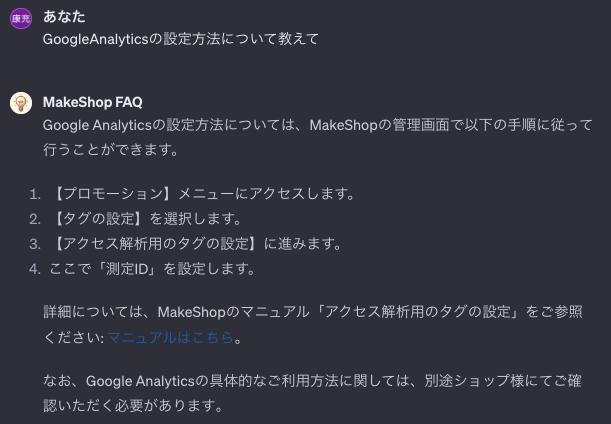
無事に回答することが出来ました。回答内容も問題ありません。このレベルで回答してくれるなら言うことありません🙆♂️
しかし、もう少し難しい問題をその後に続けてみたところ、今ひとつ回答の精度はよくありませんでした。
特に 回答が見つからない、わからない場合にエラーになるケースが目立ちました。
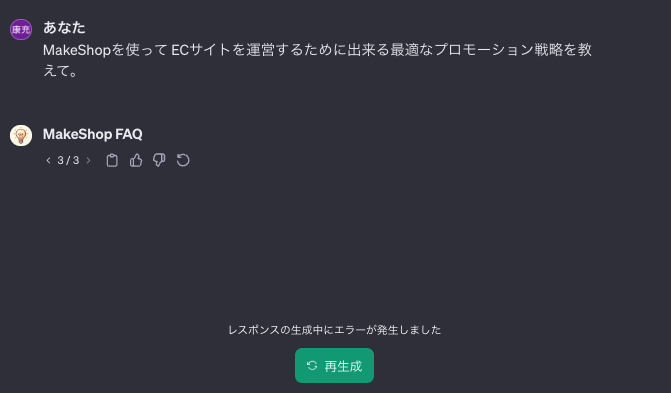
私が愛した AI の力はこんなものでは無いと思うので、ここからはチャットボットの精度を 改善 していきたいと思います。
GPTsを改善する
コンフィグファイルを変更して再度クロールする
回答内容にメインの回答文以外の共通的な要素(バナー、サイドナビの情報)が含まれているため、main-content のIDが設定されているタグの情報のみを抽出するように selector を設定します。
また、HTML以外のコンテンツは取得する必要はないので、 resourceExlusions を設定して不要な拡張子の情報へはアクセスしないようにします。
この設定を入れることで、先程 403 エラーとなっていた箇所が解消されるようになります。
コンフィグファイルの変更点
selector: '#main-content', resourceExclusions: [ 'png', 'jpg', 'jpeg', 'gif', 'svg', 'css', 'js', ・・・中略 ],
上記の変更を加えて、再度クロールします。
変更後は JSONファイルのサイズが 2560KB まで削減できました。
4580KB -> 2560KB ですので、半分近くまでファイルを縮小することが出来ました。
JSONの中身もメインコンテンツ(html)部分がグッとスッキリしました。
{
"title": "『ドメイン管理画面』のアクセス方法を教えてください。 – makeshop よくある質問",
"url": "https://help.makeshop.jp/hc/ja/articles/7891718609689--%E3%83%89%E3%83%A1%E3%82%A4%E3%83%B3%E7%AE%A1%E7%90%86%E7%94%BB%E9%9D%A2-%E3%81%AE%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E6%96%B9%E6%B3%95%E3%82%92%E6%95%99%E3%81%88%E3%81%A6%E3%81%8F%E3%81%A0%E3%81%95%E3%81%84-",
"html": " 『ドメイン管理画面』のアクセス方法を教えてください。\n2023年07月13日 00:26 更新\n\n※記載の設定メニューは、旧管理画面となります。\n 新管理画面の設定メニューについては、画面対応表よりご確認ください。\n\n \n\nmakeshopと独自ドメイン両方をご契約中の場合は、\n【管理画面右上ショップID】 > 【契約・お支払い情報】 > 【ドメイン管理画面】からログインできます。\nショップ管理画面にログイン認証をする際に、ドメイン用\n管理画面もあわせて認証しますので、二重のログイン操作は不要となります。\n※ドメイン管理画面からは、ログインIDの確認やパスワードの変更ができます。\n\n■マニュアル 【ドメイン管理画面】の確認方法\nhttps://ms-manual.makeshop.jp/domainmenu/#confirm\n\n独自ドメインのみご契約中の場合は、下記のページよりログインを行ってください。\n※『リリース』メニューより「解放する」をクリックした場合は、ログインできません。\n\n■ドメイン管理画面\nhttps://domain.makeshop.jp/login.html\n\n \n \n関連記事\n独自ドメインの「リリース」とは何ですか。\n『Google Analytics(GA4)の設定 eコマース対応』を利用してからコンバージョンが重複します。対策はありますか。\n 【ドメインの設定】外部ネームサーバーを利用し、wwwを利用したくありません。wwwなしでドメインを設定する方法はありますか。\n複数名で管理画面の操作はできますか。\n集客のコツを教えてください。"
},
GPTsにアップロードしているファイルを削除して、今回クロールして生成したファイルをアップロードします。
前回エラーとなった質問を投げてみます。
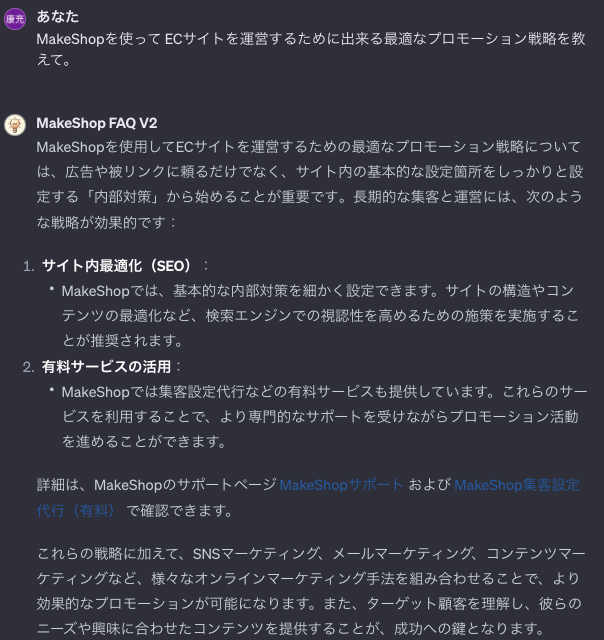
はじめに作成したGPTsではエラーとなった質問についても、無事に回答することが出来ました。
クロールする際に不要な部分を削った事で、ファイルの内容がよりFAQに関係する内容となったことで、回答精度と回答速度が向上したようです。
ただし、その後、思いつくがままに質問をしていたら、またエラーとなる問題に遭遇しました。

リポジトリーをforkしてコードを変更して再度クロールする
HTMLタグのIDにmain-contentが設定してある範囲のテキストを取得していますが、 main-contentの中にも実際の回答部分は .article-body のクラスの中なので、ここに限定した情報だけを取得できるようにしたいです。
ただ、クロールを開始するページには .article-body のクラスが含まれていないため、単純に selector で絞り込むとそもそもクロール自体が上手く行われませんでした。
※ selector で絞り込んだ範囲に存在する リンクを元に再帰的に検索するため。
そこで、以下の改修を行いました。
- 検索を開始するURLを複数設定できるようにする
- selectorで絞り込む範囲と 実際にテキストを抽出する selectorを分けられるようする
また、標準のままだと重複するURLについてもクロールされていたため、URLの重複は除外するようにしました。
他にも エスケープされた URLを decodeURIComponent で日本語として識別できる形にしたり、タイトルに共通して付与される不要な文字を除去するようにしたり、メイクショップのFAQサイトから取得するデータを最適化するための処理を組み込みました。
上記の変更を加えてクロールしたところ、ファイルサイズは 708KB まで削減することが出来ました。
4580KB -> 2560KB -> 708KB ですので、当初ファイルの20%以下まで圧縮しています。
初めに抽出したときと比べるとJSONファイルもだいぶスッキリして読みやすいものになりました。
{
"title": "『ドメイン管理画面』のアクセス方法を教えてください。",
"url": "https://help.makeshop.jp/hc/ja/articles/7891718609689--ドメイン管理画面-のアクセス方法を教えてください-",
"html": "※記載の設定メニューは、旧管理画面となります。 新管理画面の設定メニューについては、画面対応表よりご確認ください。 makeshopと独自ドメイン両方をご契約中の場合は、 【管理画面右上ショップID】 > 【契約・お支払い情報】 > 【ドメイン管理画面】からログインできます。ショップ管理画面にログイン認証をする際に、ドメイン用 管理画面もあわせて認証しますので、二重のログイン操作は不要となります。※ドメイン管理画面からは、ログインIDの確認やパスワードの変更ができます。■マニュアル 【ドメイン管理画面】の確認方法 https://ms-manual.makeshop.jp/domainmenu/#confirm 独自ドメインのみご契約中の場合は、下記のページよりログインを行ってください。※『リリース』メニューより「解放する」をクリックした場合は、ログインできません。■ドメイン管理画面 https://domain.makeshop.jp/login.html"
},
2回目の時と同様に、プロンプトは変更しないでGPTsのJSONファイルを差し替えます。
2回目のGPTsでエラーとなった質問を行います。


無事に回答することが出来るようになりました🎉
その後もしばらく質問を続けてみましたが、「私の知識に含まれていないという」という回答はありましたが、エラーになることはありませんでした。
やはり、ファイルサイズが大きいと検索と回答作成に時間が掛かりタイムアウトエラーになっているのではと思います。
まとめ
GPTsは 現状では自社サービスに組み込んで表示させるような使い方ができないので、FAQボットも 社内利用しか出来ないですが、Open AI API などを使って自前で独自DBを用いたサービスを作る場合、データクレンジングはやはり重要になると感じました。
技術は常に進化していますが、それを追いかけることで、私たちはより良いサービスを提供できるようになると思います。
「常に変化し続ける」をモットーに、これからも新しいものを追い続けていきたいです。
Enjoy your AI life.