GMOメイクショップ コアグループ エンジニアの越川です。 前職あたりから、AWS関連の仕事をさせてもらうことが多くなってきていて、 弊社の新システムの構成や構築を設計経験させていただきました。 今回は、監視について記載させていただきます。
1. 全体構成図
早速ですが、今回構築した全体図から

2. 監視対象
今回導入した各項目は後述いたします。
3. ログ監視
現行システムはCloudWatchの料金が課題の一つとなっておりました。 そのため、今回の構成では、以下の整理を行いました。
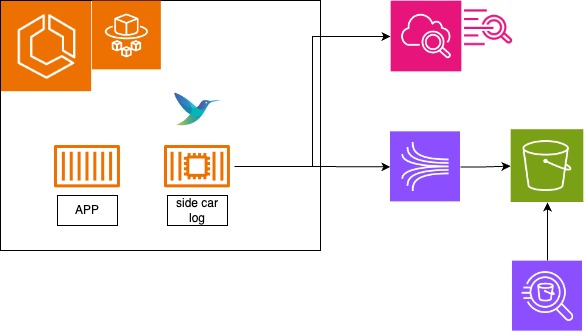
ログルーターのサイドカーを用意して、以下で分けました。 アラートが発砲したら、AthenaでS3のログを検索して調査します。
- ログレベルがエラー以上のログ:CloudWatchLogs→CloudWatchメトリクスフィルター→CloudWatch Alarm→SNS→Chatbot→Slack
- ログの全量:Kinesis Data Firehose→S3
具体的な設定ファイルは以下のような形で準備しました。
FROM amazon/aws-for-fluent-bit:latest COPY ./conf/* /fluent-bit/etc/ RUN yum install -y gcc make tar curl lua-devel && \ curl -L https://www.kyne.com.au/~mark/software/download/lua-cjson-2.1.0.tar.gz -o lua-cjson-2.1.0.tar.gz && \ tar -xzf lua-cjson-2.1.0.tar.gz && \ cd lua-cjson-2.1.0 && \ make && \ make install && \ cd .. && \ rm -rf lua-cjson-2.1.0 lua-cjson-2.1.0.tar.gz RUN yum remove -y gcc make tar RUN yum clean all
※Luaを使って、出力ログを加工しているので、いくつかのライブラリをインストールしていますが、そういう用途がなければ、最初の2行で動くと思います。
[SERVICE]
Flush 1
Grace 30
Parsers_File /fluent-bit/etc/parsers.conf
# ECSからのログ入力値を250MBに制限
[INPUT]
Name forward
unix_path /var/run/fluent.sock
Mem_Buf_Limit 250MB
# ログ項目にcontainer_idを追加
[FILTER]
Name lua
Match *-firelens-*
Script add_container_id.lua
call add_container_id
# ログ項目のみをFilter
[FILTER]
Name parser
Match *-firelens-*
Key_Name log
Parser json
# ヘルスチェックアクセスを除外
[FILTER]
Name grep
Match *-firelens-*
Exclude $msg ^(?=.*healthcheck\.Check).*$
Exclude $msg ^(?=.*grpc\.health).*$
# エラーログにタグ付け
[FILTER]
Name rewrite_tag
Match *-firelens-*
Rule $level (error|fatal) error-$container_id false
# CloudWatch出力
[OUTPUT]
Name cloudwatch_logs
Match error-*
region ap-northeast-1
log_group_name [log_group_name]
log_stream_name [log_stream_name]
auto_create_group false
workers 1
auto_retry_requests On
retry_limit 5
net.keepalive Off
#S3出力
[OUTPUT]
Name kinesis_firehose
Match *
region ap-northeast-1
delivery_stream [delivery_stream]
confファイルは大体こんな感じで用意しました。OutPutの部分で切り分けています。 こちらのDockerfileを使って、サイドカー用のイメージを作成し、ECRにPushします。
{
"containerDefinitions": [
{
### 本体のログ設定をawsfirelensにする
"logConfiguration": {
"logDriver": "awsfirelens",
"secretOptions": null,
"options": {
"Name": "stdout"
}
},
"volumesFrom": []
},
### サイドカー用の設定 追加 ###
{
### 上でPushしたイメージを指定
"image": "*********.dkr.ecr.ap-northeast-1.amazonaws.com/fluent-bit-test:latest",
"firelensConfiguration": {
"type": "fluentbit",
"options": {
"config-file-type": "file",
"config-file-value": "/fluent-bit/etc/*********.conf"
}
},
"name": "log_router"
}
### サイドカー用の設定 追加 ###
]
}
ECS側の設定はこんな感じです。簡単ですね。
4. メトリクス監視
ECSやRedisなどのメトリクスの監視を行います。 メモリ、CPUの使用率が閾値超えたら、オートスケールを行いつつ、Slackにも通知がくるようにしました。
ログと同じく、メトリクスフィルターでコンテナやRedisの使用率を測って、閾値超えたらアラートが発砲するようになっています。
通知の流れは、メトリクスフィルターで検知した閾値越えを、エラーログと同じフローでSlackまで流しています。
5. 外形監視
Synthetics Canariesを使用して、コンテナの外形監視を行います。 ヘルスチェック用のエンドポイントに向けて、リクエストを投げて、監視しています。 具体的に設定しているの以下の通りです。
const { URL } = require('url'); const synthetics = require('Synthetics'); const log = require('SyntheticsLogger'); const syntheticsConfiguration = synthetics.getConfiguration(); const syntheticsLogHelper = require('SyntheticsLogHelper'); const loadBlueprint = async function () { // ヘルスチェック用のエンドポイントを指定 const urls = ['https://xxxxx/check']; ~~~ 中略 ~~~ } const loadUrl = async function (page, url, takeScreenshot) { ~~~ 中略 ~~~ } await synthetics.executeStep(stepName, async function () { const sanitizedUrl = syntheticsLogHelper.getSanitizedUrl(url); domcontentloaded = true; // 戻り値を検証する page.goto(url, { waitUntil: ['domcontentloaded'], timeout: 30000}) .then(response => { const status = response.status(); const statusText = response.statusText(); logResponseString = `Response from url: ${sanitizedUrl} Status: ${status} Status Text: ${statusText}`; //If the response status code is not a 2xx success code if (response.status() < 200 || response.status() > 299) { throw `Failed to load url: ${sanitizedUrl} ${response.status()} ${response.statusText()}`; } return response.json() }) .then(data => { if (data.Status != "SERVING") { throw `Bad Status :${response.json()}` } }) }); ~~~以下略~~~
通知のフローはこちらもメトリクスフィルターで異常を拾ってSlackまで流し込んでいます。
5. まとめ
この仕組みを作って運用を開始し、お客様からお問い合わせいただく前にエンジニアがエラーについて検知し、 予め確認することができたり、大分運用がしやすくなったと思います。 ただ、まだ改善すべき点がある仕組みだと思いますので、これからも改善していきたいです。 導入してみて、成果があった監視や記事に関して、ご意見・ご感想を頂けますと幸いでございます。